Форма входа |
|---|
Категории раздела | |
|---|---|
|
Поиск |
|---|
Наш опрос |
|---|
Друзья сайта |
|---|
|
|
Статистика |
|---|
Онлайн всего: 1 Гостей: 1 Пользователей: 0 |
Я - Аналитик!
Каталог статей
| Главная » Статьи » Опыт моделирования на UML » Повышение производительности аналитика |
Моделирование "Видения"
Небольшое предисловиеМеня часто спрашивают: "Вы что же, считаете, что модели следует использовать для документирования? А Вы книжки читаете? Даже "отцы-основатели" рекомендуют не абсолютизировать модели и использовать их, в основном, для обсуждения проектных решений. В крайнем случае, для генерации кода!" Часто хочется ответить: "А Вы обратили внимание, когда написали это "отцы-основатели"?" Менее, чем в течение жизни одного поколения ЭВТ и соответствующие технологии сделали огромный скачок от нуля до сегодняшнего состояния. Кому-то это может показаться фантастикой, но свою первую программу (расчетная часть дипломного проекта) я написал в 1964 году на вполне современной (для того времени) ЭВМ "Минск-1" (ОП = 512 байт!). Развитие техники и технологии (в том числе, технологии разработки программ) идет нарастающими темпами, иногда – скачкообразно. Один из таких скачков – появление в 2004 году концепции MDA и языка UML2. По моему мнению, следствием этого события должно стать переосмысление роли моделирования в разработке ПО, и, в частности, к строгости моделирования и к поддержанию моделей в актуальном состоянии. Если раньше необходимость поддержки строгости и актуальности моделей определялась по критерию "трудозатраты – степень полезности", то в технологии MDA вопрос решается однозначно: "из неактуальной модели может быть порождена только неактуальная модель и неактуальный код". Конкуренция толкает поставщиков средств моделирования и разработки ПО на включения в свои продукты поддержки MDA, в частности, удобных средств создания и выполнения преобразований "модель – модель", "модель – код", "код – модель" самими пользователями преобразований[1]. Проблема документированияПерманентная строгость и актуальность модели позволяет по-новому поставить вопрос отношения моделирования и документирования[2]. Существование проблемы документирования вряд ли кто-нибудь из практикующих разработчиков будет отрицать[3]. Речь идет не только о пользовательской документации, которая, обычно, выполняется постфактум и почти никогда не бывает актуальной. Не меньше неприятностей доставляет документация для разработчиков. Проектные группы периодически "кошмарят" изменения требований или проектных решений, которые "существуют" только в мозгу человека, сделавшего соответствующее изменение. Существование строгой и актуальной модели, содержащей всю определенную на данный момент проектную информацию – эффективное решение проблемы документирования[4]. Большинство инструментов моделирования и разработки имеют средства генерации отчетов. Многие из них имеют средства для создания шаблонов произвольных отчетов. Если ваш инструмент поддерживает MDA (и соответственно сертифицирован), он должен иметь средство создания преобразований моделей в текст. Если это не так, инструмент не поддерживает MDA, и, может быть, следует подумать о его замене. Аргумент против
автоматизации документирования – сложность создания шаблонов. Другой аргумент –
увеличение нагрузки при моделировании, необходимость документирования модельных
элементов, которые будут представлены в отчетах. Зачем и как моделировать документ "Видение"Для многих аналитиков составляет определенную трудность создание главного документа требований (в технологии RUP) – "Видение" (Vision). Главное отличие документа "Видение"Назначение проектной документации состоит в том, чтобы показать, что и как должно быть сделано и как это сделанное должно работать. Ответы на вопросы "почему" обычно относятся к области предпроектных исследований. Эти соображения относятся и к проектной документации в сфере разработки ПО, и, в частности, к документам RUP. На мой взгляд, "Видение" – это единственный аналитический документ в наборе проектной документации RUP[7]. В отличие от других документов требований (например, "Спецификация требований" или ТЗ), "Видение" сообщает не только то, "что" должна делать система, но и логически выводит эти "что" из проблем и потребностей заинтересованных лиц. Зачем это нужно? Вот как описывается назначение "Видения"
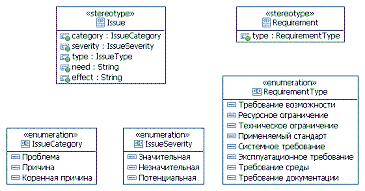
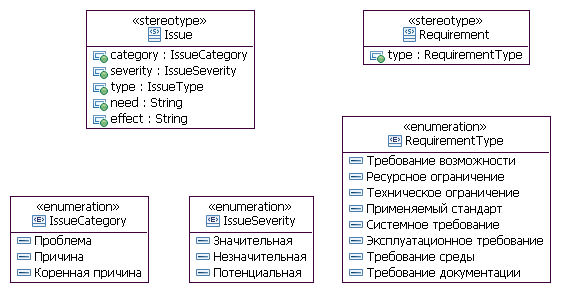
в RUP (с небольшими сокращениями): В условиях итерационного инкрементного процесса разработки грамотные формулировки документа "Видении" помогут избавиться от разночтений при детализации высокоуровневых требований в процессе выполнения проекта. При возникновении конфликта детализации требования, определенного в "Видении", нужно "сместиться влево" в цепочке "проблема – причина – потребность – ожидаемый эффект – требование возможности" и решить, необходимо ли это детальное требование для разрешения проблемы. К сожалению, мой опыт консультирования и проектов внедрения свидетельствует о непонимании многими аналитиками назначения "Видения". Чаще всего этот документ рассматривается как "бесполезная необходимость" и работа анализа заменяется формальным заполнением стандартного шаблона. Приспосабливание шаблонаШаблон RUP для документа "Видение" на русском языке[8] доступен для скачивания в приложении к этой статье. Как все шаблоны RUP, этот общий шаблон (RUP Видение.dot) создан на все случаи жизни, которые никогда не происходят все вместе. Содержание документа (или типового шаблона) должно быть приспособлено к ситуации. Пожалуй, прежде всего, из шаблона нужно исключить все, что мешает "увидеть лес за отдельными деревьями". Простой пример – всегда ли нужны разделы "Демография рынка" и/или "Альтернативы и конкуренция"? Чаще всего – нет. Документ "Видение" инициализируется после заключения договора на разработку, когда разговоры о конкурентах уже закончены! Ну, а если на рынке есть похожие решения, пусть разработчики подумают, как их использовать. А это уже не предмет документа требований. Нужно убрать информацию, содержащуюся в других проектных документах (например, в "Плане управления требованиями"), многочисленные повторения и постараться сделать документ лаконичным, содержащим только то, что действительно обеспечивает его соответствие основному назначению. Шаблон Видение.dot, применяемый в организации-разработчике проекта "Система управления оказанием услуг", который я использую в качестве примера в этом цикле статей, доступен для скачивания в приложении. Расширенное моделированиеКогда аналитик встречается с заинтересованным лицом (заказчиком), чаще всего, он спрашивает: "Чего Вы хотите от разрабатываемой системы?". Или еще чаще: "Какой должна быть разрабатываемая система?". С точки зрения теории решения изобретательских задач[9] это неверно, т.к. ответ на такой вопрос существенно ограничивает область возможных решений проектной группы. Правильный первый вопрос: "Какие проблемы Вы испытываете при существующей технологии работы?". Заинтересованное лицо редко может сразу правильно указать свои истинные проблемы. Задача аналитика – помочь заинтересованному лицу определить и документировать в документе "Видение" его коренную проблему (проблемы) и фундаментальную (конечную, коренную) причину (причины) каждой проблемы, возможное решение и ожидаемый эффект. Эта триада (коренная причина, решение и ожидаемый эффект) представляет исходную информацию для определения каждого требования возможности. В общем случае, определение коренной проблемы и фундаментальной причины – задача далеко не тривиальная. RUP рекомендует использовать в процессе мозгового штурма диаграммы рыбьей кости (Fishbone Diagram)[10] и диаграммы Парето. Метод эффективный. Его возможности распространяются далеко за границы задачи исследования причинно-следственных связей при разработке ПО. С моей точки зрения, этот метод имеет один недостаток: отсутствие возможности использования в модели и средств автоматизированного документирования совместно с другими модельными элементами UML. Я использую собственную технологию моделирования причинно-следственных связей проблем разработки ПО (в частности – моделирования документа "Видение") и "делюсь" ей со слушателями курсов и клиентами в проектах внедрения технологии RUP. Технология базируется на создании диаграмм объектов UML, элементами которой являются экземпляры трех базовых классов: "Заинтересованное лицо", "Проблема" и "Требование". Соответствующие стереотипы определены в профиле UML UPIA. Правда, я использую собственный профиль AddUPIAProfile. Со стереотипами этого профиля ассоциированы перечисления с литералами на русском языке. На диаграмме ниже представлены только два стереотипа. Моделирование заинтересованных лиц подробно описано в статье "Моделирование заинтересованных лиц в TOGAF".
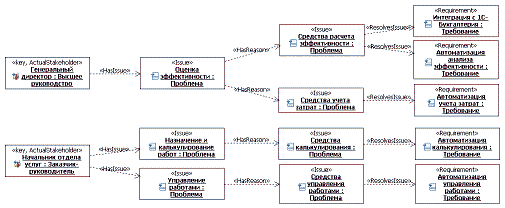
Дополнительно, в этом профиле создано три стереотипа для зависимостей: HasIssue (Имеет проблему), HasReason (Имеет причину) и ResolvesIssue (Разрешает проблему). В модели может быть представлено множество диаграмм, отображающих причинно-следственные связи. Каждая начинается с заинтересованного лица (заинтересованных лиц) и завершается требованием (требованиями) с неограниченным количеством последовательных проблем между ними (первая слева определяется как проблема, далее причины этой проблемы и т.д.; самая правая причина – это фундаментальная причина, которая реализуется требованием). Документ "Видение" – это уже результат анализа причинно-следственных связей проблем. В соответствии с шаблоном, в документе указываются только проблемы и их фундаментальные причины. Для нашего примера диаграмма (несколько сокращенная) имеет вид:
Отчет, сгенерированный из этой модели (vis__ВидениеRpt.doc) можно скачать в приложении. Очень советую посмотреть! Обратите внимание: то, что напечатано черным – это элементы шаблона или то, что не моделировалось. Синим шрифтом напечатана информация из модели. Примечание: В связи с тем, что, по информации статистики, модели и публикации моделей в приложениях не пользуются спросом читателей, я приостанавливаю их публикацию. Публикация моделей и/или веб-публикаций моделей может быть возобновлена при обращении читателей. [1] В RSA, например, такой инструмент позволяет создавать преобразования в код для любого языка, метамодель которого определена. Другое дело – целесообразность создания "собственного" языка программирования. [2] Я уже кратко касался этого вопроса в первом выпуске цикла, в разделе "Модель первична, документ – вторичен". [3] Я знаю случай, когда заказчик два года не подписывал приемный акт из-за неготовности пользовательской документации! [4] Существует мнение, что
поддержка актуальности модели чересчур затратна. Так ли это? [5] В приложении ко второму выпуску цикла представлен пример спецификации бизнес-процесса. Там же – исходная бизнес-модель (оригинал и публикация в виде HTML). [6] Самый "черный"
вариант использования модели для документирования: создать документ Word, содержащий структуру
документа. В нужные места структуры скопировать соответствующие фрагменты из
модели. [7] Кого-то из аналитиков это может обидеть, но позволю себе высказать следующую мысль: Если роль системного аналитика в проекте состоит только в описании требований к системе, то его скорее можно назвать "постановщиком задачи", "описателем требований". И только его ответственность за создание документа "Видение" дает ему право называться аналитиком! [8] Перевод мой. [9] Проект разработки серьезной программной системы без натяжки можно считать изобретательской задачей. [10] Эту диаграмму также называют диаграммой Исикавы. См., например, http://www.tools-quality.ru/index.php/q7/isikava | |
| Просмотров: 4046 | Комментарии: 15 | Рейтинг: 0.0/0 |
{kind=link}
{kind=link}
| Всего комментариев: 15 | ||||||||||||
| ||||||||||||